鹅厂开源视频生成大杀器!参考图主体精准复刻,还能编辑现有视频
刚刚,鹅厂开源 " 自定义 " 视频生成模型 HunyuanCustom。
" 自定义 " 主打的就是主体一致性,用一张图片就可以确定视频主角,其一致性评分达到了开源模型 SOTA,且可和闭源媲美。
这样在构思提示词时,就可以不必纠结主体特征描述了。

HunyuanCustom 一共支持单主体参考、多主体参考、局部编辑、角色配音四大功能。
其中单主体参考已上线并开源,其余也将在本月内开源。
此外混元的技术人员还在直播中透露,团队正在和开源社区合作,将适配 AI 创作者常用的 ComfyUI。
期待所有功能完整上线的同时,不妨先来看看 demo 效果!
主体一致性达到 SOTA
先看已经上线的单主体参考,我们可以分成人类和非人类两个部分来看。
人物部分,提示词如下:
A woman takes a selfie in a busy city. A woman holds a smartphone in one hand and makes a peace sign with the other. The background is a bustling street scene with various signs and pedestrians.
参考译文:一位女士在繁忙的城市中自拍。她一手拿着智能手机,一手比耶。背景是熙熙攘攘的街景,各种招牌和行人熙熙攘攘。
可以看到,参考图中人物的五官、发色、服饰等特征,包括项链这样的细节,都得到了很好的保留。

还有这位男士,即使跨越吃早餐、搭乘地铁、工作、陪小狗散步等不同场景,人物特征也能保持不变。

除了人,小动物的特征也可以保持一致,比如下面这段视频当中,参考主体是小狗,正在公园当中追逐一只小猫(猫由模型自由生成)。

在后续,多主体参考功能也将上线并开源,先来看下两个主体都是人的情况。

On the modern city streets, a man asks a woman for directions, but she doesn ’ t understand what he ’ s saying.
参考译文:在现代城市的街道上,一个男人向一个女人问路,但她听不懂他在说什么。
画面当中,男性角色是以侧脸方式呈现的,与照片中的角度明显不同,但看上去很像同一个人。

再看人和非人物体,这里有一只小企鹅。

A man is sitting in a spacious and bright living room, smiling and greeting a cute penguin. The penguin nods back at him in a friendly manner, as if responding to his greeting.
参考译文:宽敞明亮的客厅里,一位男士正微笑着与一只可爱的企鹅打招呼。企鹅也友好地点头示意,仿佛在回应他的问候。
具体的表现,直接看结果:

在人与非人的多参考主体组合中,还有一种比较特殊的类型就是服装,特殊性主要体现在其融合程度相对其他物体更深。

A man wearing Hanfu walks across an ancient stone bridge holding an umbrella, raindrops tapping against it.
参考译文:一名身着汉服的男子撑着伞走过一座古老的石桥,雨滴轻敲着桥面。

实际场景当中,多主体参考功能在制作广告的任务当中尤其好用,混元团队还在论文当中专门展示了几组广告制作场景。

除了根据现有主体生成全新的视频之外,HunyuanCustom 也可以对已有的视频进行局部编辑。
例如在这个海底场景当中,Hunyuan 对其中的一条鱼进行了成功替换。

在遮罩、原视频和目标对象被输入 HunyuanCustom 后,原来位置的小丑鱼变成了一只金鱼。

此外 HunyuanCustom 还支持音频驱动,只需要上线一段音频和参考图,即可生成口型匹配的视频。
另外,如果没有具体的朗读文本,也可以让模型来合成,不过目前语音合成的声音还是有一点机械感。
混元团队介绍,这一问题仍在完善过程当中。
A single person, in the dressing room. A woman is holding a lipstick, trying it on, and introducing it.
参考译文:试衣间里,一个人。一位女士正拿着一支口红,正在边试用边介绍。
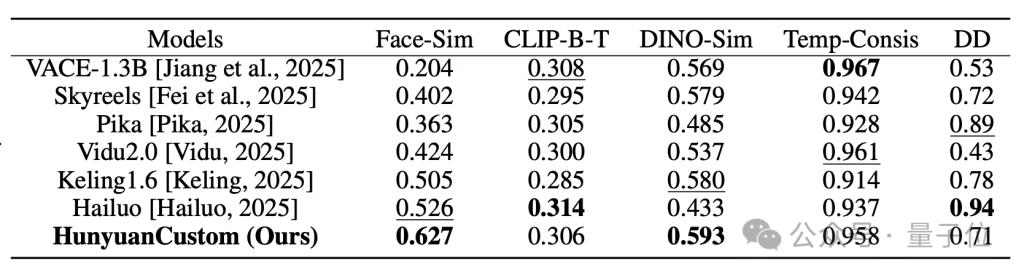
测评数据方面,在单主体视频定制任务中,作者将 HunyuanCustom 与现有的视频定制方法进行了比较,包括开源模型开源模型如 Skyreels-A2 和 VACE,也包括一些知名的商业模型。
结果,HunyuanCustom 在身份一致性(Face-Sim)和主体相似性(DINO-Sim)两个指标上达到了最佳表现,分别为 0.627 和 0.593,超过了所有 baseline 方法。
对于其他功能,技术报告中也展示了一些定性比较:

配置方面,目前 HunyuanCustom 支持 720P 画质,如果自行部署,需要支持 CUDA 的英伟达 GPU。
GitHub 项目页中介绍,用 HunyuanCustom 生成 720P 视频,最少需要 24GB 显存,但速度会很慢,因此推荐配置仍为 80GB。
那么,HunyuanCustom 究竟是如何实现的呢?
一个结构实现多种能力
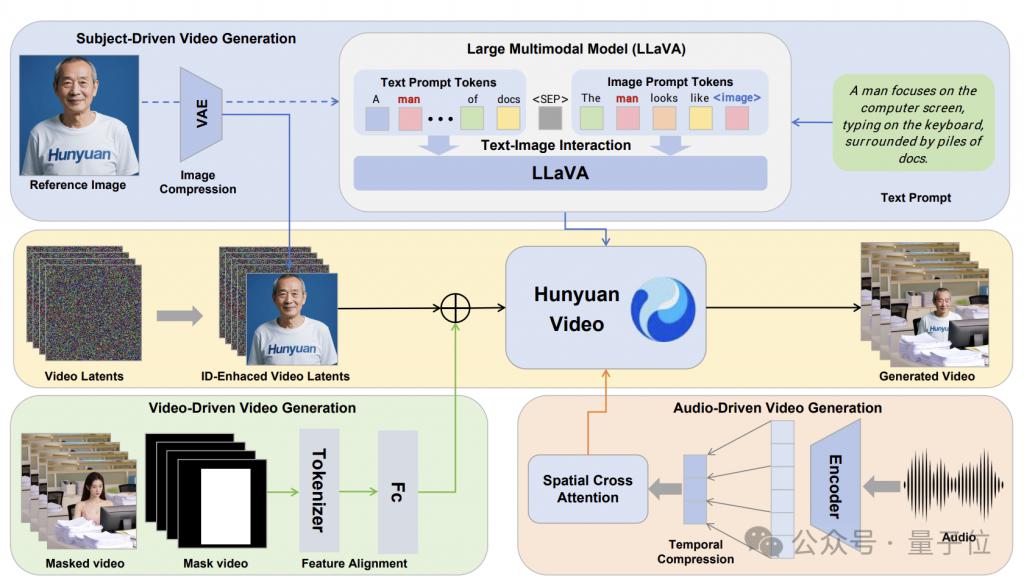
HunyuanCustom 以文生视频模型 HunyuanVideo 为基础,并分别针对不同的任务类型配备了相应的模块。
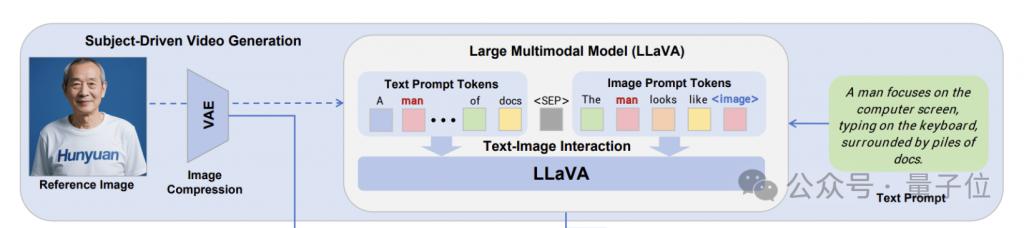
先看图像驱动的生成任务(单 / 多主体参考),这一部分的两个核心,分别是 LLaVA 文本 - 图像交互模块和身份增强模块。
LLaVA 文本 - 图像交互模块的目的是增强模型对输入图像所表示身份信息的理解,并将其与文本描述进行有效融合。
具体而言,给定文本输入、图像输入以及图像在文本中对应的描述词,该模块设计了两种融合模板:
图像嵌入模板:将文本描述中的图像描述词替换为特殊的图像 token。例如,对于文本提示 "A man is playing guitar",如果输入的是 "man" 的身份图像,则处理后的模板为 "A is playing guitar";
图像附加模板:在文本描述之后添加一个身份提示,例如 "A man is playing guitar. The man looks like "。
处理后,会被替换为 LLaVA 提取的 24 × 24 的图像隐藏特征。
尽管 LLaVA 模块能够捕捉文本和图像之间的高层语义关联,但它主要关注类别、颜色和形状等高级特征,却没有关注到文本、纹理等精细的图像细节,而这些细节对于保持身份一致性至关重要。
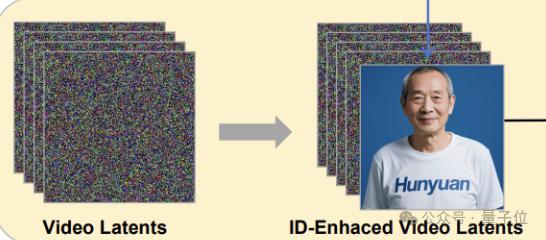
为了进一步增强生成视频的身份一致性,HunyuanCustom 设计了身份增强模块。
其核心是将表示身份的图像特征连接到视频的每一帧上,利用视频生成模型在时间维度上的建模能力,使身份信息在生成视频的各个帧之间得到有效传播和增强。
具体来说,HunyuanCustom 先将输入图像通过预训练的 3D-VAE 编码器映射到潜空间,得到图像潜码,然后将其与视频潜码在序列维度上进行连接,形成新的潜码表示。
特别地,在多身份视频定制任务中,HunyuanCustom 将单身份定制模型作为基础,并进行了相应的扩展——
给定多个身份图像和对应的文本描述,HunyuanCustom 首先对每个图像 - 文本对进行 LLaVA 交互建模,然后将所有图像编码为潜空间表示,并与视频潜码进行连接。
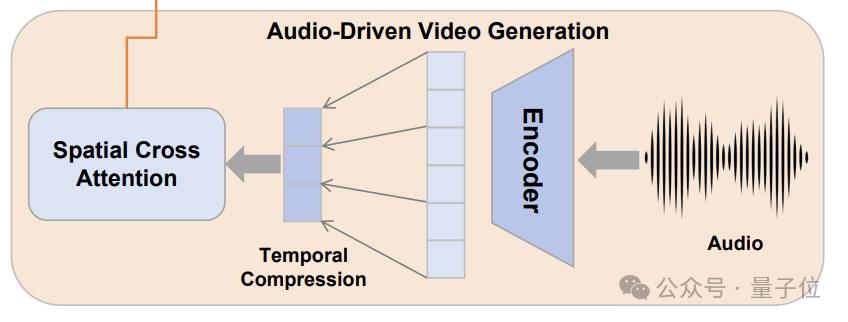
再看音频驱动(角色配音)部分,HunyuanCustom 在这一模块中使用的是身份解耦的 AudioNet 模块,目的是确保音频条件的引入不会干扰到人物身份的一致性。
具体而言,给定一个长度音频 - 视频序列,AudioNet 首先对每一帧音频进行特征提取,得到一个特征张量。
由于视频潜码在时间维度上经过了压缩,因此还需要对音频特征进行相应的时间对齐,最终得到一个与视频潜码在时间维度上完全对齐的音频特征张量。
之后,AudioNet 通过一个交叉注意力模块将音频信息注入到视频潜码中。为避免不同帧之间音频和视频信息的相互干扰,AudioNet 采用了逐帧的空间交叉注意力机制。
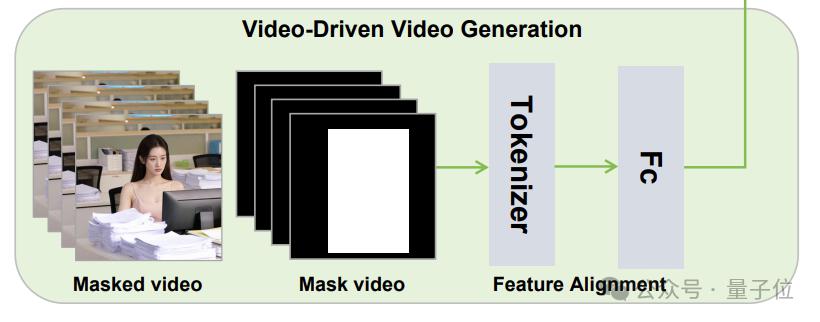
最后是视频驱动(局部编辑),这部分采用了视频条件注入策略。
HunyuanCustom 首先使用预训练的 3D-VAE 将输入的源视频编码到潜空间,得到压缩后的视频特征表示。
接下来,HunyuanCustom 通过一个特征对齐网络将压缩后的视频特征映射到与视频潜码相同的特征空间中,使其与视频潜码在时空维度上完全对齐。
在对齐视频条件特征和视频潜码后,HunyuanCustom 探索了两种不同的条件注入方式 :
特征拼接:将对齐后的视频条件特征与视频潜码在特征维度上进行拼接,然后通过一个线性变换层将拼接后的特征重新投影回原始的潜码空间;
特征叠加:直接将对齐后的视频条件特征逐帧叠加到视频潜码上,保持特征的维度不变。
实验结果表明,特征拼接的方式容易导致视频内容信息的丢失和压缩,生成的视频质量和连贯性较差。
相比之下,特征叠加的方式能够更好地保留视频条件中的时空信息,并与视频潜码进行无缝融合。
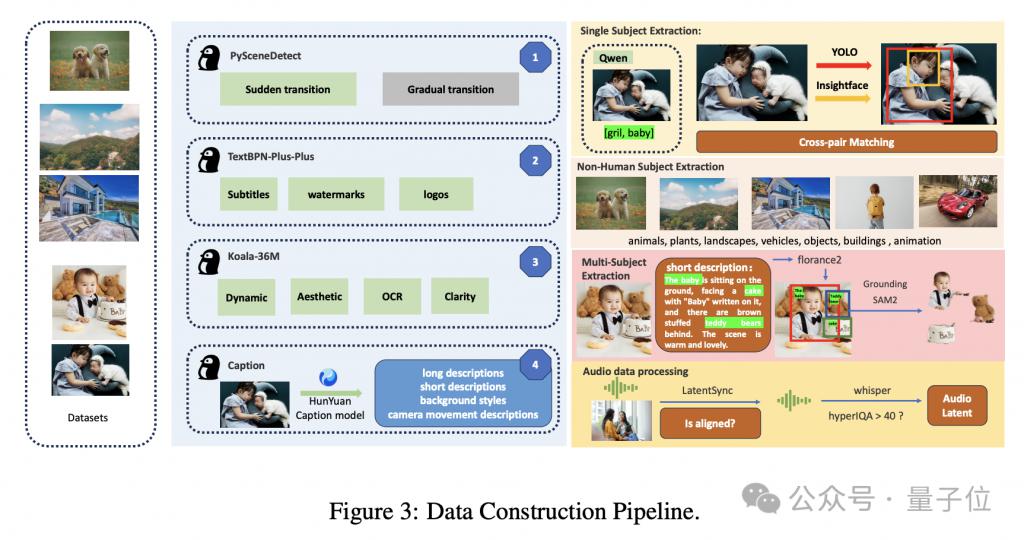
为了进一步提高模型的泛化能力和鲁棒性,HunyuanCustom 在训练时采用了一系列数据增强策略。
例如,通过随机扰动掩码边界、将掩码转化为边界框等方式,增加了掩码的多样性和不确定性,使得模型能够更好地适应不同形状和大小的编辑对象。
此外,HunyuanCustom 还通过数据收集筛选和一系列质量算子,获得了高质量的训练样本。
另外在训练过程中,混元团队还采取了 Flow Matching 框架来优化视频生成模型。
该框架通过最小化模型预测的视频潜码演化速度与真实速度之间的均方误差,来学习视频的时间动态。
具体而言,给定一个视频片段的起始潜码和结束潜码,以及表示身份的参考图像,模型学习预测视频潜码在不同时间步上的演化方向和速度,并以最小化速度重建误差为目标进行优化。
除了 Flow Matching 损失外,HunyuanCustom 还引入了辅助损失函数,以实现多任务学习和模块间的协同优化。
通过联合优化损失函数,不同模块间建立起了有效的约束和协同,最终使生成视频在多个方面达到更好的平衡和表现。
在推理阶段,HunyuanCustom 首先通过对应的特征提取器,将这些多模态输入转化为适合跨模态交互的特征表示。
然后,这些特征表示按照预定的流程,根据实际任务情况匹配对应的模块,与生成视频的中间特征进行逐步融合。
去年 12 月,混元文生视频功能正式上线;今年 3 月,混元团队又推出了图生视频,两项功能都是发布即开源。
那么,你认为混元的视频生成,还有这次新增的 " 自定义 " 功能符合你的期待吗?欢迎评论区交流。
项目主页:
https://hunyuancustom.github.io/
GitHub:
https://github.com/Tencent/HunyuanCustom
Hugging Face:
https://huggingface.co/tencent/HunyuanCustom
论文地址:
https://arxiv.org/abs/2505.04512
— 完 —
量子位 AI 主题策划正在征集中!欢迎参与专题365 行 AI 落地方案,一千零一个 AI 应用,或与我们分享你在寻找的 AI 产品,或发现的AI 新动向。
也欢迎你加入量子位每日 AI 交流群,一起来畅聊 AI 吧~
一键关注 点亮星标
科技前沿进展每日见
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!